The Ohio State University
NVIDIA
NVIDIA
NVIDIA
The Ohio State University
NVIDIA
CVPR 2025 Oral (0.74%)
*Work partly done during Nvidia internship, +Contact: song.1855@osu.edu
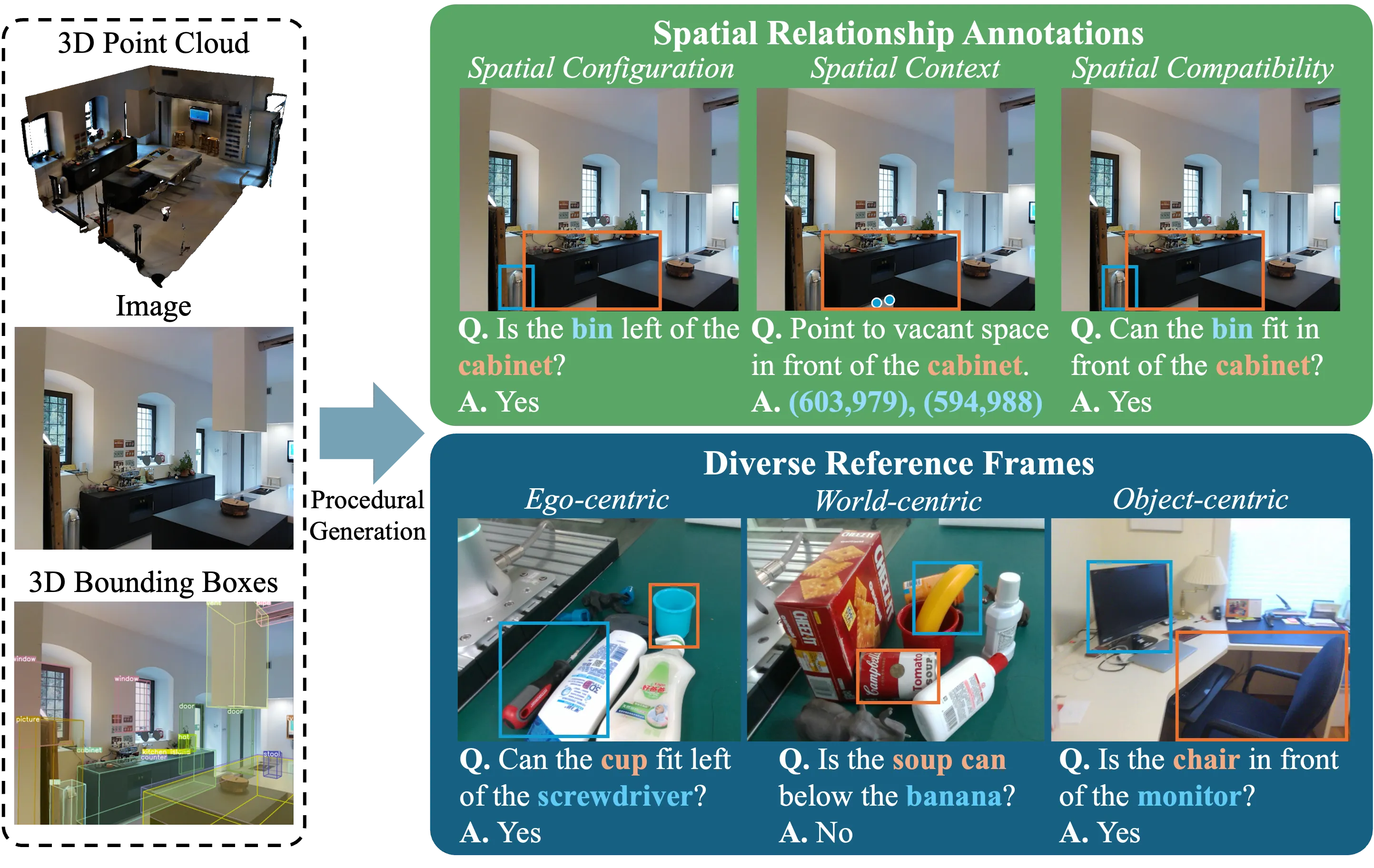
TL;DR A large-scale 2D/3D dataset of real indoor/tabletop environments for spatial reasoning in robotics.
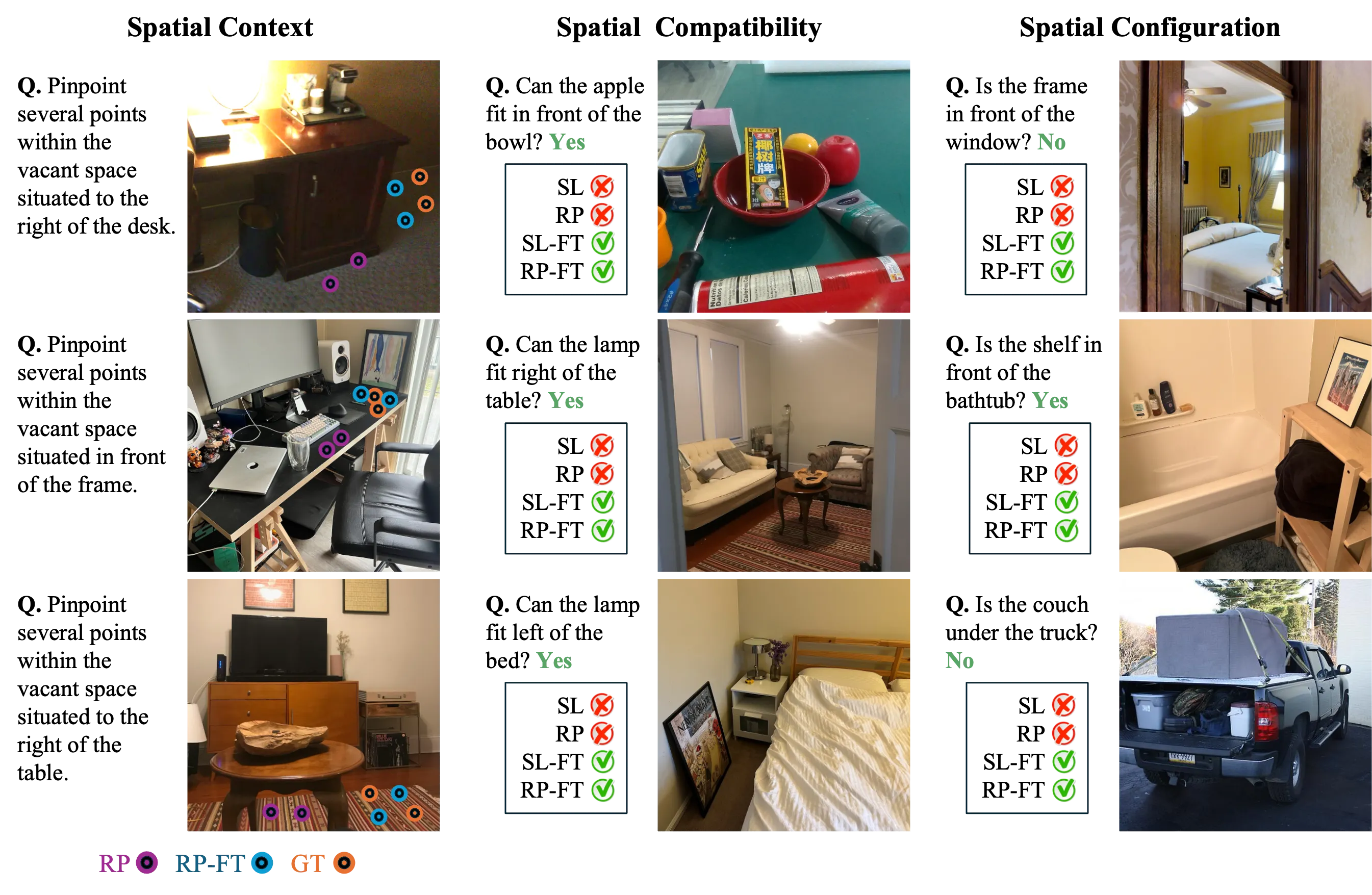
Spatial understanding is essential for robots to perceive, reason about, and interact with their environments. However, current visual language models often rely on general-purpose image datasets that lack robust spatial scene understanding and reference frame comprehension (ego-, world-, or object-centric). To address this gap, we introduce RoboSpatial, a large-scale dataset of real indoor and tabletop environments captured via egocentric images and 3D scans. RoboSpatial provides 1M images, 5k 3D scans, and 3M annotated spatial relationships, enabling both 2D and 3D spatial reasoning. Models trained on RoboSpatial outperform baselines on tasks including spatial affordance prediction, spatial relationship prediction, and robot manipulation.

| Model | RoboSpatial-Val | RoboSpatial-Home | BLINK-Spatial | SpatialBench-Position |
|---|---|---|---|---|
| Open-source | ||||
| —2D— | ||||
| LLaVA-NeXT (8B) | 30.3 | 46.3 | 71.8 | 55.9 |
| + RoboSpatial | 60.5 | 59.6 | 79.0 | 70.6 |
| RoboPoint (13B) | 38.9 | 53.4 | 63.6 | 44.1 |
| + RoboSpatial | 70.6 | 63.4 | 70.6 | 64.7 |
| —3D— | ||||
| Embodied Generalist (7B) | 42.8 | 29.8 | N/A | N/A |
| + RoboSpatial | 71.9 | 43.8 | N/A | N/A |
| Baselines | ||||
| Molmo (7B) | 50.1 | 25.6 | 67.1 | 55.9 |
| GPT-4o | 50.8 | 47.0 | 76.2 | 70.6 |

| Model | Success Rate (%) |
|---|---|
| Open-source | |
| LLaVA-NeXT (8B) | 23.7 |
| + RoboSpatial | 52.6 |
| Baselines | |
| Molmo (7B) | 43.8 |
| GPT-4o | 46.9 |
@inproceedings{song2025robospatial,
author = {Song, Chan Hee and Blukis, Valts and Tremblay, Jonathan and Tyree, Stephen and Su, Yu and Birchfield, Stan},
title = {{RoboSpatial}: Teaching Spatial Understanding to {2D} and {3D} Vision-Language Models for Robotics},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
note = {To appear},
}