The Ohio State University
Google Cloud AI Research
Google Cloud AI Research
The Ohio State University
Google DeepMind
Google Cloud AI Research
Google Cloud AI Research
CVPR 2026
*Joint last authors, Contact: chanhee.luke@gmail.com, {yiwensong, oriva, hamidpalangi}@google.com
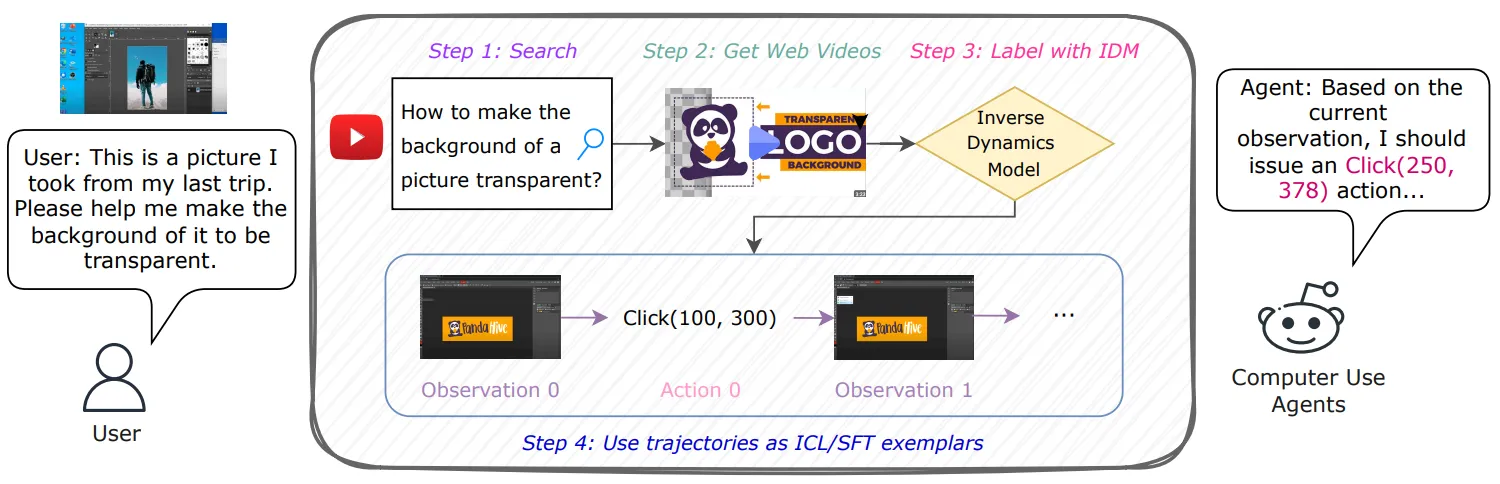
TL;DR A framework leverages inverse dynamics to convert internet videos of human computer use into executable UI trajectories, significantly improving computer-using agent performance.
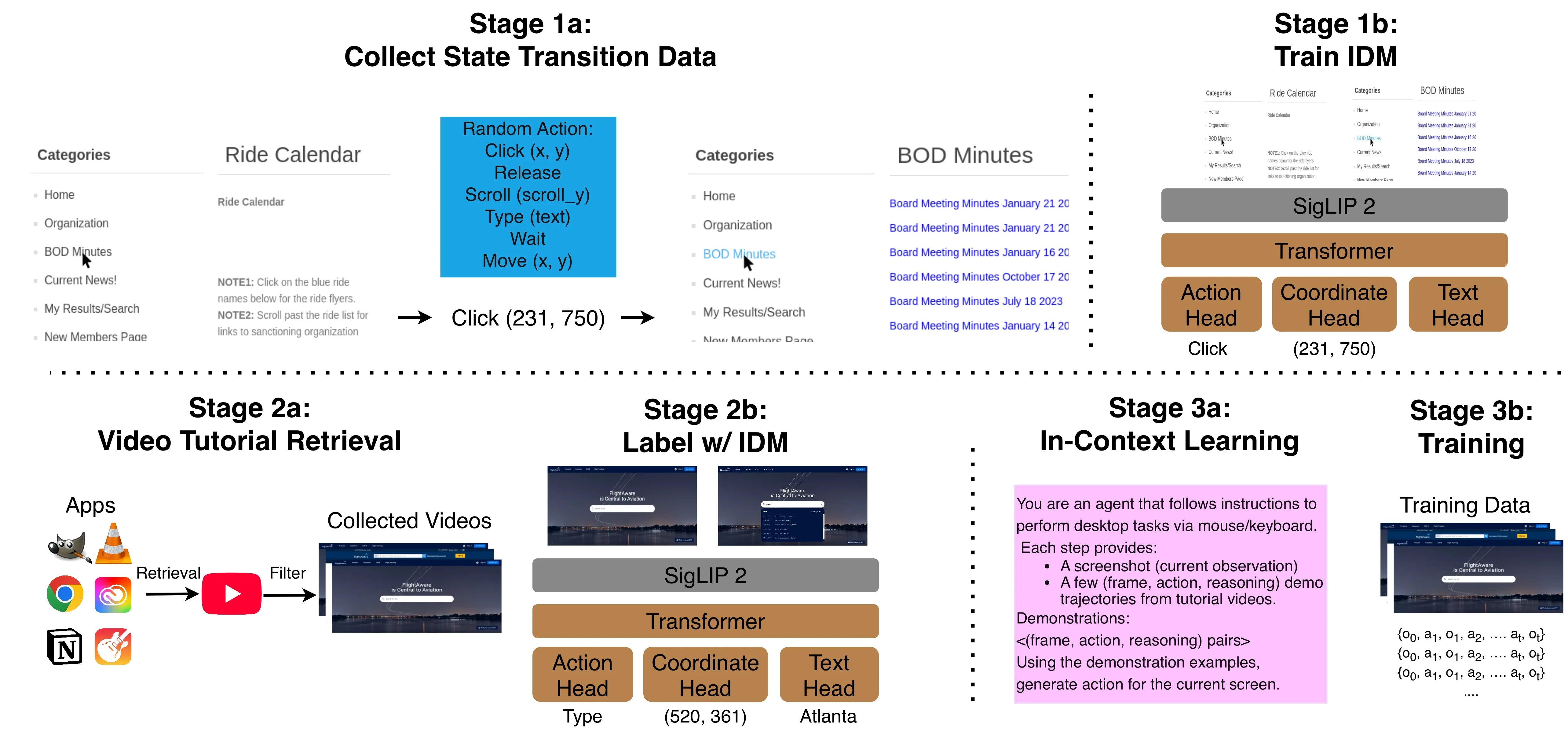
Watch and Learn (W&L) is a scalable framework that transforms everyday Internet videos of people using software into executable user interface action trajectories for training computer-using agents. Instead of relying on costly manual annotation or synthetic data that can produce oversimplified behaviors, W&L formulates trajectory extraction as an inverse dynamics problem, predicting user actions directly from consecutive screen states. This approach simplifies learning and generalizes across diverse and evolving applications. Through a task aware retrieval and labeling pipeline, the framework produces more than 53,000 high quality trajectories that can be used both as supervised training data and as in-context examples. Experiments on OSWorld and WindowsAgentArena show consistent improvements for both general purpose and specialized agents with supervised fine-tuning and in-context learning. Watch and Learn demonstrates that web scale human demonstration videos provide a practical and scalable foundation for advancing real world computer-using agents.
| ActionType | Gemini 2.5 Flash | TongUI | Ours |
|---|---|---|---|
| click(x, y) | 68% | 72% | 95% |
| release | 71% | 67% | 90% |
| scroll(scroll_y) | 55% | 75% | 93% |
| type(text) | 77% | 71% | 86% |
| wait(500ms) | 92% | 88% | 97% |
| move(x, y) | 65% | 61% | 89% |
| ActionType Accuracy | 81.5% | 84.3% | 95.8% |
| Action Accuracy | 70.5% | 72.3% | 91.7% |

| Model | Setting / Training Data | Success Rate (%) |
|---|---|---|
| UI-TARS-1.5-7B | Base (No SFT) | 18.1 |
| SFT w/ TongUI | 12.9 (-5.2) | |
| SFT w/ W&L (IDM-labeled) | 24.0 (+5.9) | |
| OpenCUA-7B | Base (No SFT) | 13.5 |
| UltraCUA-7B | Base (No SFT) | 21.7 |
| Category | Base Model | Method | Success Rate (%) |
|---|---|---|---|
| General Models | Gemini 2.5 Flash | Base (w/o video) | 19.0 |
| ICL w/ W&L labeled videos | 22.0 (+3.0) | ||
| OpenAI o3 | Base (w/o video) | 21.8 | |
| ICL w/ TongUI labeled videos | 21.1 (-0.7) | ||
| ICL w/ W&L labeled videos | 24.3 (+2.5) | ||
| Claude 4 Sonnet | Base (w/o video) | 43.9 | |
| ICL w/ TongUI labeled videos | 43.4 (-0.5) | ||
| ICL w/ W&L labeled videos | 45.5 (+1.6) | ||
| Agentic Framework | Jedi | Base (w/o video) | 50.6 |
| ICL w/ W&L labeled videos | 52.8 (+2.2) |
| Category | Base Model | Method | Success Rate (%) |
|---|---|---|---|
| Open-Source Models | Qwen 2.5VL 7B | Base (No SFT) | 1.9 |
| SFT w/ TongUI labeled | 5.4 (+3.5) | ||
| SFT w/ W&L (IDM labeled) | 13.0 (+11.1) | ||
| UI-TARS-1.5-7B | Base (No SFT) | 27.3 | |
| SFT w/ TongUI labeled | 23.8 (-3.5) | ||
| SFT w/ W&L (IDM labeled) | 31.1 (+3.8) |
@inproceedings{song2026watchandlearn,
author = {Song, Chan Hee and Song, Yiwen and Goyal, Palash and Su, Yu and Riva, Oriana and Palangi, Hamid and Pfister, Tomas},
title = {{Watch and Learn: Learning to Use Computers from Online Videos}},
booktitle = {{Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2026},
note = {To appear},
}